Build a Client Preference Ledger Before AI Recommends Neighborhoods
Build a Client Preference Ledger Before AI Recommends Neighborhoods
AI is getting pulled into the home search at the exact point where buyer language is least precise. A client says they want a quiet neighborhood, better schools, a safe area, a short commute, more walkability, or a place that feels like their current community. A model can turn those phrases into a ranked list in seconds. That speed is useful only if the brokerage has already defined what the system is allowed to infer, what it must ask back, and what evidence it can use.
The operating answer is a client preference ledger: a structured record of buyer-approved criteria, source evidence, and review triggers that sits between the CRM, saved search, listing alerts, and any AI recommendation layer. The ledger does not make the agent less personal. It protects the personal advice from becoming undocumented judgment.
This matters now because buyers are already assuming AI is inside the transaction. Cotality's April 2026 homebuyer research found that three quarters of buyers expect AI to play a role somewhere in the process, while U.S. trust in AI for finding a home has fallen. NerdWallet's 2026 home buyer report separately found that nearly half of prospective buyers have used or plan to use AI during the process. The market is not waiting for perfect governance. Buyers are bringing AI expectations into the search, and teams need a practical control before recommendations become invisible steering.
The Risk Is Not The Recommendation. It Is The Unlogged Translation.
Most real estate teams already collect preferences, but they collect them as notes: "likes walkable areas," "wants good schools," "prefers safe neighborhood," "near family," "avoid busy roads," "more space," "better commute." Notes help a human remember context. They are weak inputs for automation.
The risky moment happens when a system translates those notes into filters or rankings without preserving the buyer's own definition. "Walkable" could mean a ten-minute walk to coffee, a sidewalk route to a park, access to transit, or fewer car trips for errands. "Short commute" could mean peak-hour travel time, predictable travel time, access to one office, access to two employers, or school drop-off compatibility. "Quiet" could mean not backing to a major road, fewer shared walls, distance from nightlife, or simply a preference for a cul-de-sac.
If the AI makes that translation silently, the team cannot explain why a listing was included, why a neighborhood was excluded, or whether the recommendation came from the buyer's criteria or from the model's assumptions. That is the workflow failure to fix.
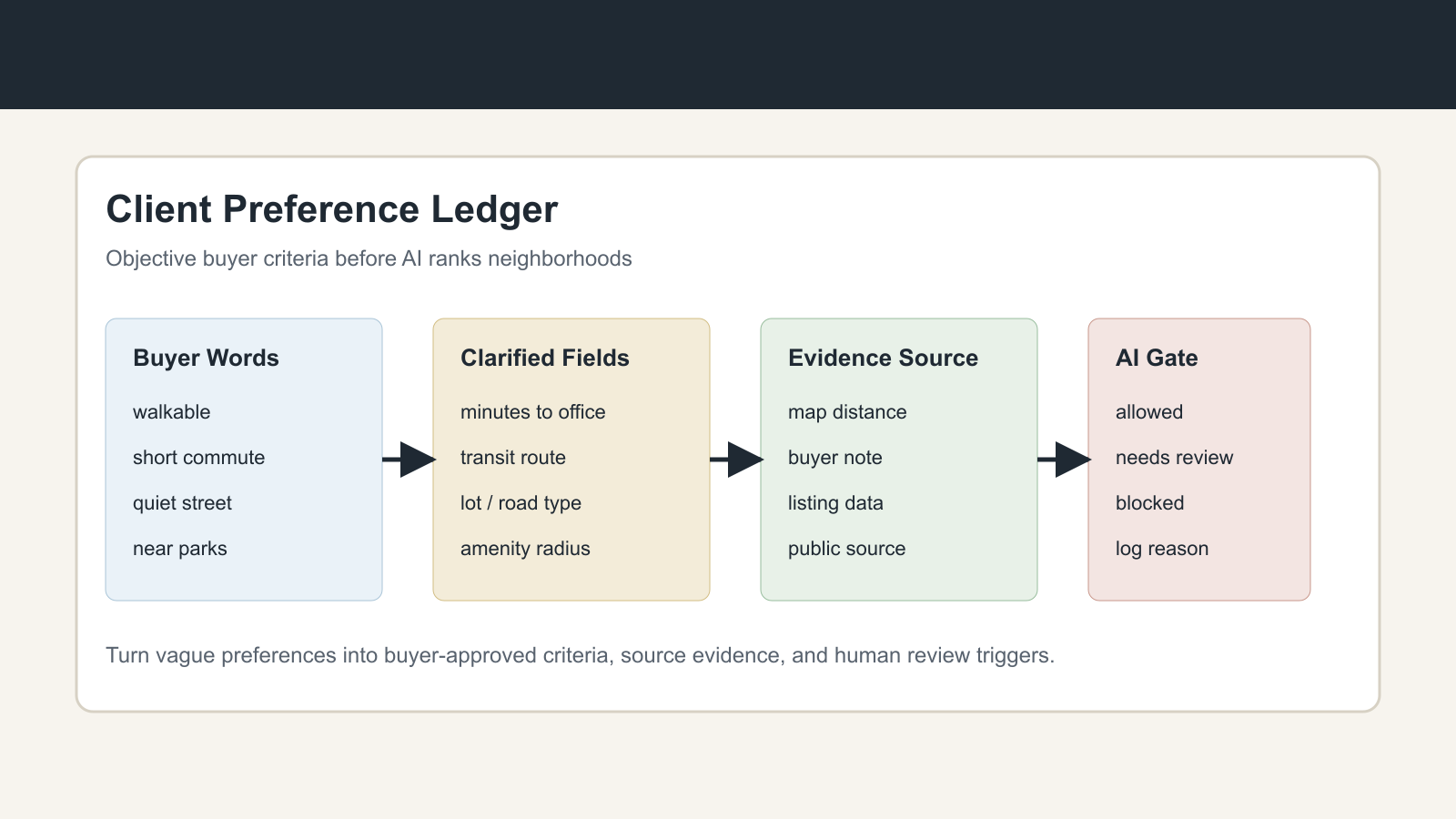
A Preference Ledger Has Five Fields
A usable ledger does not need to be complicated. It needs to be specific enough that AI can operate inside it and humans can audit it later.
First, capture the buyer phrase exactly. Preserve the words the client used before anyone translates them. This protects context and makes it easier to ask a precise follow-up.
Second, convert the phrase into an objective criterion. "Close to work" becomes a commute-time range from a named origin to a named destination. "Near parks" becomes a distance or travel-time radius to a public amenity. "Low maintenance" becomes property attributes like age of major systems, HOA coverage, yard size, or exterior material. The goal is not to flatten the client; it is to make the operational version of the preference testable.
Third, record the evidence source. Some criteria come from MLS fields, some from public maps, some from buyer-provided locations, and some from agent observation during showings. AI should not treat all evidence as equal. A buyer's written preference, a map calculation, and an agent's opinion should be labeled differently.
Fourth, set the automation permission. Some preferences are safe for AI to apply directly, such as bedroom count, price range, commute radius, or property type. Others should trigger a clarification step before the system changes a search. Others should be blocked from autonomous use and routed to a human review.
Fifth, keep a change log. Preferences drift. Buyers tour homes and learn what they actually value. A ledger should show who changed the criterion, when it changed, what triggered the change, and whether the buyer confirmed it. Without that history, AI may interpret browsing behavior or a single showing comment as permission to rewrite the search.
Fair Housing Makes The Ledger More Important, Not Less
Fair housing rules do not mean buyers should receive less information. HUD's April 2026 statement says real estate professionals may discuss school quality and crime data when they do so consistently, without discriminatory intent, and without using protected characteristics to influence choice. HUD's Fair Housing Act overview still makes the baseline clear: discrimination in buying, renting, mortgage access, and other housing-related activity remains illegal across protected classes.
That combination is exactly why the ledger matters. The operational standard is not silence. It is consistency, source discipline, and buyer-defined criteria.
NAR's steering guidance is still useful at the workflow level. When clients use vague terms like good, nice, or safe, agents should clarify the objective criteria instead of substituting personal judgments about communities. A preference ledger turns that guidance into a system behavior. The AI should ask, "What does safe mean for your search: lighting, traffic speed, proximity to public data sources, property condition, or something else?" It should not decide that one community is safe and another is not.
For teams using AI, the compliance exposure is often hidden in ranking logic. If the system boosts or suppresses areas because of unapproved proxies, the agent may not notice until a client asks why certain listings never appeared. The ledger gives the team a reviewable artifact: the recommendation used these buyer-approved fields, these sources, and these constraints.
Where To Put It In The Stack
The preference ledger should sit upstream of three workflows.
Put it before saved-search automation. AI should not widen, narrow, or reorder search alerts because it inferred a lifestyle preference from chat history. It should propose a change, show the evidence, and ask for confirmation when the criterion is material.
Put it before neighborhood recommendation content. If the team sends market updates, relocation guides, school-area summaries, commute comparisons, or lifestyle-oriented email campaigns, the copy should reference objective buyer criteria and public sources. Avoid language that labels communities in broad subjective terms.
Put it before agent-assist drafting. When AI drafts replies, showing summaries, or buyer consultation notes, it should pull from the ledger rather than from raw memory. The draft can say, "You told us you want a commute under 35 minutes to the downtown office and sidewalks within a half mile," because those are buyer-defined criteria. It should not say, "This is a better neighborhood for your family," because that is a loaded conclusion without an objective basis.
The Weekly Review Is The Control
A ledger is only useful if someone reviews exceptions. The weekly review should be short and mechanical.
Start with changed preferences. Which buyer criteria changed this week, and were those changes explicitly confirmed? Then review blocked terms. Which prompts or notes included vague neighborhood language that AI was not allowed to operationalize? Then review recommendation gaps. Which listings were excluded by AI filters, and would a reasonable human have expected the buyer to see them? Finally, review source quality. Which recommendations relied on public data, MLS fields, buyer-provided facts, or agent judgment?
This review gives the broker or team lead a way to improve the system without rereading every client conversation. It also creates a better coaching loop. Agents learn which phrases need clarification, admins learn which fields the CRM should support, and the AI workflow gets cleaner inputs over time.
The Practical Build
Start with one buyer segment, not the entire CRM. A good first segment is active buyers receiving automated listing alerts or AI-assisted follow-up.
Add ledger fields for buyer phrase, objective criterion, evidence source, permission level, owner, last confirmed date, and review status. Use simple permission levels: allowed, clarify, human review, and blocked. Add a reason field so reviewers can see whether the issue is fair housing sensitivity, weak evidence, stale buyer confirmation, or missing source data.
Then update prompts and automations so AI can only make neighborhood or lifestyle recommendations from ledger-approved criteria. If the buyer phrase has not been converted into an objective criterion, the system should ask a clarification question. If the source is weak, the system should label the output as a draft and route it to a human. If the term touches protected-class risk or subjective community judgments, the system should stop and request review.
The business benefit is not only risk reduction. The buyer experience gets better. Clients see recommendations tied to their actual priorities, not generic neighborhood narratives. Agents spend less time reverse-engineering why the system picked a listing. Team leaders gain an audit trail before a complaint, a confused client, or a missed opportunity forces the issue.
AI can be helpful in the home search, but it should not invent the buyer's values. Build the ledger first. Let the model rank, draft, and summarize only after the team has turned preference into evidence.

Written by
Ben Laube
AI Implementation Strategist & Real Estate Tech Expert
Ben Laube helps real estate professionals and businesses harness the power of AI to scale operations, increase productivity, and build intelligent systems. With deep expertise in AI implementation, automation, and real estate technology, Ben delivers practical strategies that drive measurable results.
View full profile